
- 1 - Análisis de rendimiento de Meridian
- 2 - 1. Contexto y Objetivo
- 3 - 2. Entorno de Pruebas y Metodología
- 4 - Entorno
- 5 - Metodología
- 6 - Script de referencia
- 7 - 3. Perfiles de Datos Probados
- 8 - 4. Pipeline Completo — Tabla Maestra TF vs JAX
- 9 - Tiempos (segundos)
- 10 - Memoria delta (MB)
- 11 - Lectura rápida de la tabla
- 12 - 5. MCMC de Producción
- 13 - Resultados
- 14 - Coste proyectado en producción
- 15 - 6. Análisis de Causas Raíz
- 16 - 6.1 El MCMC es el cuello de botella dominante — y es inevitable
- 17 - 6.2 Por qué TF tarda más que JAX en MCMC
- 18 - 6.3 Por qué el Analyzer tarda 7.2s siempre en TF — y 0.25s en JAX
- 19 - 6.4 Por qué el sample_prior tarda más en JAX (~4.5s vs ~0.7s TF)
- 20 - 6.5 Por qué el BudgetOptimizer escala con canales, no con geos
- 21 - 6.6 VIF a escala extrema — solo relevante con >50 geos
- 22 - 7. Qué se Puede Mejorar y Qué No
- 23 - ✅ Mejoras con evidencia real y ganancia confirmada
- 24 - ❌ No vale la pena o directamente no aplica
- 25 - 8. Roadmap de Optimización — Alto Nivel
- 26 - Prioridad 1 — Migrar a backend JAX
- 27 - Prioridad 2 — GPU para el sampler MCMC
- 28 - Prioridad 3 — Paralelizar cadenas MCMC en CPU
- 29 - Prioridad 4 — VIF paralelo (solo si habitualmente >50 geos)
- 30 - 9. Datos Pendientes
- 31 - Mediciones completadas
- 32 - Mediciones completadas
- 33 - Pendiente de medir
- 34 - 10. Conclusión
- 35 - Apéndice — Archivos de Referencia
Análisis de rendimiento de Meridian
Fecha: 18 de junio de 2026 Proyecto: google/meridian Datos: pichu2707/meridian-analisis
Subiré en el proyecto toda la documentación que tenemos y hemos usado para que se vea el estudio de manera más detallada.
1. Contexto y Objetivo
Pues vamos a meternos de lleno en esto. Antes de empezar con números, conviene entender qué es lo que estamos midiendo y por qué.
Google Meridian es una librería open-source de Marketing Mix Modeling (MMM) — una técnica estadística que ayuda a las empresas a responder una pregunta que siempre está sobre la mesa: ¿cuánto de mis ventas vienen realmente de cada canal de marketing? ¿Cuánto aporta la TV, cuánto el digital, cuánto el search? Meridian lo resuelve con un enfoque bayesiano, es decir, construye un modelo probabilístico que aprende de los datos históricos y estima el impacto de cada inversión.
Para hacerlo, usa MCMC (Markov Chain Monte Carlo) — un método matemático que, en lugar de buscar una única respuesta exacta, genera miles de escenarios posibles y los combina para dar una estimación con margen de incertidumbre. Es la forma más rigurosa de hacer este tipo de análisis, y por eso es computacionalmente intensivo. No es un defecto del software, es el precio de hacer las cosas bien.
Dentro del MCMC, el algoritmo concreto que usa Meridian se llama NUTS (No-U-Turn Sampler) — el estado del arte para este tipo de modelos. No tiene alternativa razonable sin comprometer la calidad estadística.
Objetivo de este análisis: Identificar con datos reales dónde están los cuellos de botella en el pipeline completo de Meridian antes de proponer ninguna optimización. La filosofía aquí es clara: medir primero, optimizar después. No tocar nada sin evidencia, porque optimizar lo que no es el problema real solo consume tiempo y recursos sin mejorar nada.
2. Entorno de Pruebas y Metodología
Entorno
| Parámetro | Valor |
|---|---|
| Sistema operativo | Linux |
| Python | 3.13 |
| TensorFlow | 2.20.0 |
| JAX / jaxlib | 0.7.2 |
| TFP (TensorFlow Probability) | 0.26.0.dev20260130 |
| Hardware | CPU únicamente — sin GPU ni TPU |
| Aceleración XLA | Activa en ambos backends |
Metodología
- Datos sintéticos generados con la API interna del propio Meridian:
test_utils.sample_input_data_revenue(). Usamos los datos del propio proyecto para garantizar que pasan todas las validaciones internas y son representativos de un uso real — nada inventado. - Herramientas de medición:
cProfile(mide el tiempo de CPU función por función) +tracemalloc(mide cuánta memoria consume cada fase del proceso). - Warmup explícito: antes de cada medición se ejecuta un run mínimo para forzar la carga de módulos. Esto es importante porque la primera vez que arranca el proceso hay un coste fijo de ~22 segundos y ~324 MB que no tiene nada que ver con lo que queremos medir. Lo aislamos para que los números sean limpios.
- Reproducibilidad:
seed=42fijo en todas las mediciones — así cualquier persona puede reproducir exactamente los mismos resultados.
Script de referencia
Ubicación: /tmp/opencode/meridian_synthetic_data.py
# Pipeline completo (prior, 10 draws)
python meridian_synthetic_data.py pequeno
python meridian_synthetic_data.py mediano
python meridian_synthetic_data.py grande
# MCMC de producción (4 cadenas × 1500 steps = 6000 steps totales)
python meridian_synthetic_data.py pequeno --mcmc
python meridian_synthetic_data.py mediano --mcmc
# Con backend JAX
MERIDIAN_BACKEND=jax python meridian_synthetic_data.py mediano
MERIDIAN_BACKEND=jax python meridian_synthetic_data.py mediano --mcmc3. Perfiles de Datos Probados
Se definieron 3 perfiles realistas y 1 extremo para estudiar el comportamiento de escala.
| Perfil | Geos | Ch. media | Ch. RF | Controles | Semanas | Datos (float32) |
|---|---|---|---|---|---|---|
| PEQUEÑO | 2 | 3 | 2 | 2 | 52 (~1 año) | ~0.01 MB |
| MEDIANO | 10 | 8 | 4 | 4 | 104 (~2 años) | ~0.13 MB |
| GRANDE | 50 | 15 | 6 | 6 | 208 (~4 años) | ~2.2 MB |
| EXTREMO* | 200 | 30 | 10 | 8 | 416 (~8 años) | ~31.5 MB |
*EXTREMO: caso límite, no representativo del uso habitual. Se incluye para estudiar comportamiento en condiciones de escala extrema.
El caso más habitual en producción está entre MEDIANO y GRANDE.
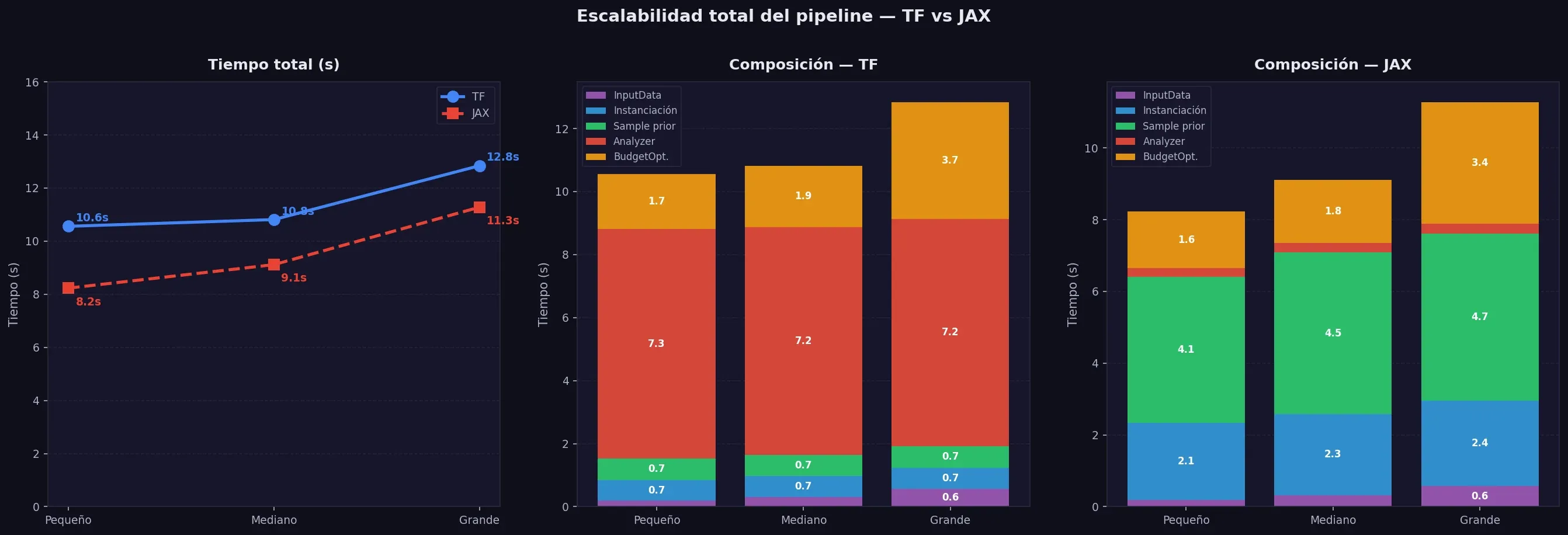
4. Pipeline Completo — Tabla Maestra TF vs JAX
Antes de medir el MCMC completo (que puede tardar horas), medimos el pipeline entero con una muestra pequeña — sample_prior(n_draws=10) — suficiente para activar todas las fases del proceso y ver dónde se va el tiempo. Aquí es donde aparece la primera sorpresa.
Comparamos dos backends de cómputo: TensorFlow (TF) y JAX — dos librerías de Google para operaciones matemáticas sobre tensores (básicamente, matrices de datos). Meridian soporta ambas, pero el comportamiento es muy diferente.
Tiempos (segundos)
| Fase | TF-P | TF-M | TF-G | JAX-P | JAX-M | JAX-G |
|---|---|---|---|---|---|---|
| 1. InputData (xarray) | 0.19 | 0.31 | 0.58 | 0.19 | 0.31 | 0.58 |
| 2. Instanciación Meridian | 0.67 | 0.67 | 0.69 | 2.26 | 2.33 | 2.42 |
| 3. Sample prior (10 draws) | 0.69 | 0.74 | 0.71 | 4.20 | 4.63 | 4.76 |
| 4. Analyzer (incremental_outcome) | 7.19 | 7.30 | 7.24 | 0.25 | 0.27 | 0.30 |
| 5. BudgetOptimizer (optimize) | 1.74 | 1.96 | 3.55 | 1.62 | 1.81 | 3.54 |
| TOTAL | 10.47 | 10.97 | 12.77 | 8.52 | 9.34 | 11.60 |
Memoria delta (MB)
| Fase | TF-P | TF-M | TF-G | JAX-P | JAX-M | JAX-G |
|---|---|---|---|---|---|---|
| 1. InputData (xarray) | 0.35 | 0.66 | 4.90 | 0.35 | 0.66 | 4.90 |
| 2. Instanciación Meridian | 3.12 | 3.14 | 3.99 | 6.86 | 6.89 | 6.89 |
| 3. Sample prior (10 draws) | 0.81 | 0.85 | 0.98 | 6.28 | 6.76 | 6.91 |
| 4. Analyzer (incremental_outcome) | 2.94 | 2.94 | 2.94 | 0.77 | 0.77 | 0.77 |
| 5. BudgetOptimizer (optimize) | 1.03 | 1.03 | 1.02 | 1.90 | 1.87 | 1.87 |
| TOTAL | 8.25 | 8.62 | 13.83 | 16.16 | 16.95 | 21.34 |
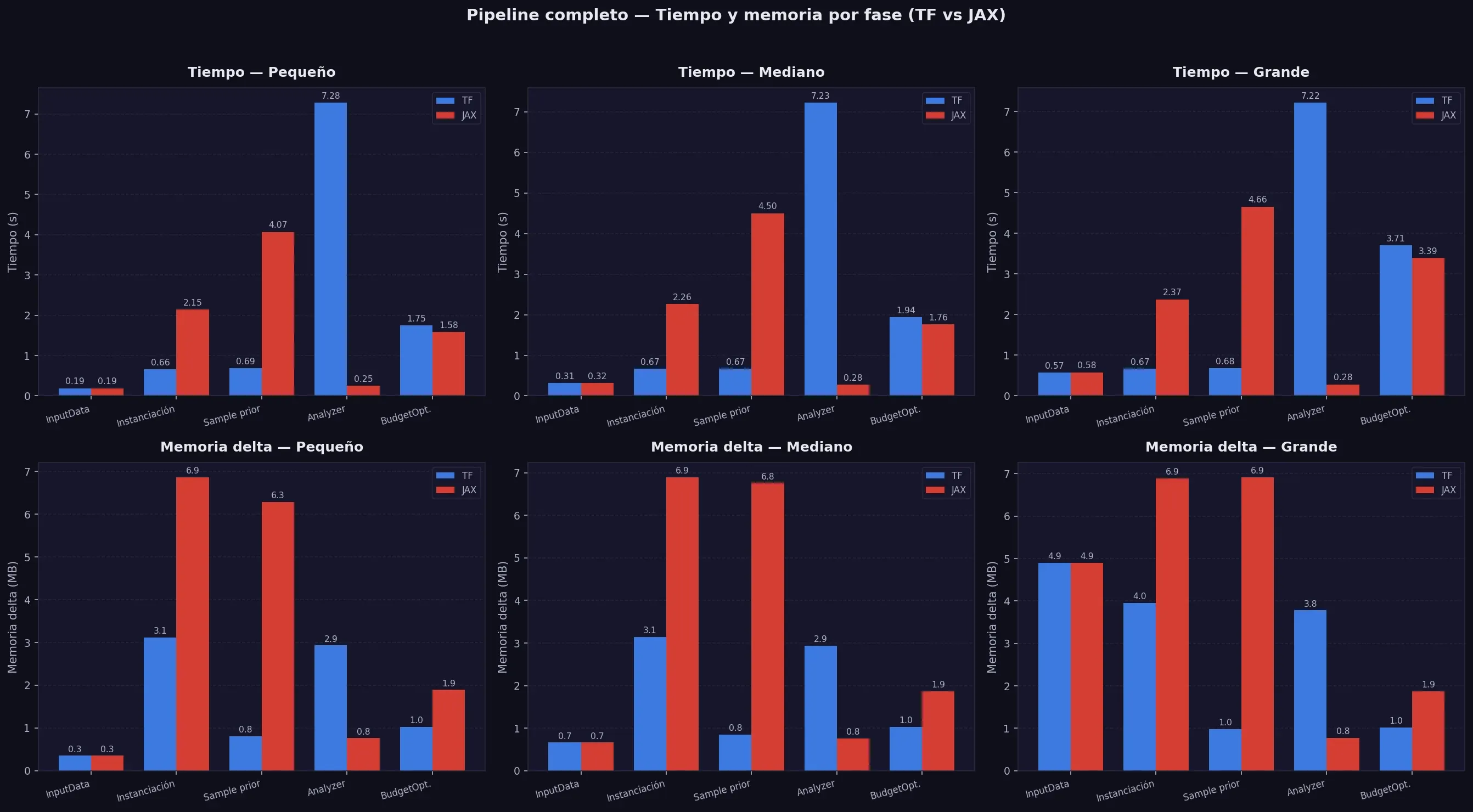
Lectura rápida de la tabla
| Fase | Comportamiento TF | Comportamiento JAX | Delta |
|---|---|---|---|
| InputData | Escala con geos×canales | Idéntico | Sin diferencia |
| Instanciación | ~0.67s constante | ~2.3s constante | JAX +1.6s (one-time) |
| Sample prior | ~0.71s constante | ~4.5s constante | JAX +3.8s (one-time) |
| Analyzer | ~7.2s constante | ~0.27s constante | JAX −28× (96% menos) |
| BudgetOptimizer | Escala con n_canales | Idéntico | Sin diferencia |
5. MCMC de Producción
Con el mapa de fases claro, pasamos a lo que importa en producción: el MCMC completo. Aquí es donde se pasan las horas reales cuando alguien ejecuta Meridian en un proyecto de verdad.
Los parámetros que usamos son los estándar en la literatura de MMM:
| Parámetro | Valor | Razón |
|---|---|---|
n_chains | 4 | Diagnóstico R-hat requiere múltiples cadenas |
n_adapt | 500 | Adaptación del step size del sampler NUTS |
n_burnin | 500 | Descarte de la fase transitoria |
n_keep | 500 | Muestras finales para inferencia |
| Steps totales | 6.000 | 4 cadenas × 1.500 steps |
Resultados
| Perfil | TF — tiempo | TF — ms/step | TF — memoria | JAX — tiempo | JAX — ms/step | JAX — memoria | Δ tiempo | Δ memoria |
|---|---|---|---|---|---|---|---|---|
| PEQUEÑO (2g/3ch) | 231s | 38 ms | 263 MB | 146s | 24 ms | 91 MB | −37% | −65% |
| MEDIANO (10g/8ch) | 549s | 91 ms | 266 MB | 356s | 59 ms | 95 MB | −35% | −64% |
| GRANDE (50g/15ch) | no medido* | — | — | no medido* | — | — | — | — |
*GRANDE: estimado >20 min en CPU. Se omite por coste de tiempo. Todos los valores son mediciones empíricas de runs completos de producción (6.000 steps).
Coste proyectado en producción
Proyecciones basadas en los ms/step medidos empíricamente, escalados linealmente:
| Escenario | Config | TF — CPU | JAX — CPU | Con GPU (est.) |
|---|---|---|---|---|
| Exploración rápida | 1 cadena, 200 steps | ~13 min | ~8–12 min | ~1-3 min |
| Run estándar | 4 cadenas, 1.500 steps | ~6-9 h | ~2.5-6 h | ~20-50 min |
| Run completo | 4 cadenas, 4.000 steps | ~16-24 h | ~7-16 h | ~1-3 h |
TF: basado en 38 ms/step (pequeño) y 91 ms/step (mediano) — medidos en run completo de producción. JAX: basado en 24 ms/step (pequeño) y 59 ms/step (mediano) — medidos en run completo de producción. GPU: estimaciones basadas en benchmarks generales TFP/JAX (5-20× sobre CPU). Requieren validación empírica.
6. Análisis de Causas Raíz
Aquí es donde los números dejan de ser solo números y empezamos a entender el porqué. Todo lo que verás a continuación está basado en lo que el profiler confirmó — no en suposiciones.
6.1 El MCMC es el cuello de botella dominante — y es inevitable
El sampler NUTS ejecuta por cada step una serie de operaciones que no se pueden saltarse:
- Evaluación del log-posterior — calcula cuánto “encaja” el modelo con los datos en ese punto. Incluye las transformaciones matemáticas de cada canal (adstock y hill — que modelan cómo se acumula y satura el efecto de la publicidad). Operación necesaria, no hay alternativa.
- Diferenciación automática — calcula el gradiente, es decir, la dirección hacia la que moverse en el espacio de parámetros. Es lo que hace que el sampler sea inteligente en lugar de aleatorio puro.
- Árbol leapfrog — el algoritmo explora varias direcciones antes de decidir. Con profundidad máxima 10, puede hacer hasta 1.024 evaluaciones del gradiente en un solo step. Esto es lo que lo hace preciso — y lento.
- Compilación XLA — la primera iteración compila el grafo de operaciones matemáticas. Solo ocurre una vez, el resto de iteraciones reutilizan la versión compilada.
El algoritmo NUTS es el estado del arte para este tipo de modelos. No tiene sustituto sin comprometer la calidad estadística — y eso no es negociable.
6.2 Por qué TF tarda más que JAX en MCMC
Aquí está la clave de todo. El profiler lo dejó muy claro.
Con TF, en solo 7 steps:
19.351.710 llamadas a builtins.isinstance → 23 segundosDiecinueve millones de comprobaciones de tipo en Python. En 7 pasos. Eso significa que el grafo de TF no está completamente compilado — hay partes del sampler que siguen ejecutando Python puro en cada iteración, en lugar de correr código compilado y optimizado. Eso es overhead puro, y escala con el número de steps.
Con JAX, el profiler muestra algo muy diferente:
14.497 llamadas a pjit.cache_miss
jax._src.linear_util.call_wrapped → 92s acumuladoJAX compila el grafo completo en la primera pasada. Una vez compilado, el bucle del MCMC ya no toca Python — corre directamente código optimizado. El coste de compilación se paga una sola vez al principio, y todas las iteraciones siguientes son más baratas.
Resultado en producción con MCMC completo (6.000 steps) — ambos backends medidos empíricamente:
- PEQUEÑO: −37% tiempo (231s → 146s), −65% memoria (263 MB → 91 MB)
- MEDIANO: −35% tiempo (549s → 356s), −64% memoria (266 MB → 95 MB)
La mejora de tiempo es consistente entre perfiles (~35-37%) — a diferencia de lo que sugerían las extrapolaciones anteriores. Y la memoria se comporta igual: JAX consume un 64-65% menos de forma constante, independientemente del tamaño del dataset.
El profiler explica el porqué. Con TF, en 6.000 steps de producción:
20.438.837 llamadas a builtins.isinstance → 23s acumulado
+55 MB tensorflow/python/framework/ops.py:266 ← nodos del grafo acumulándose
+54 MB tensorflow/python/framework/ops.py:3480 ← más nodos del grafo
+40 MB tensorflow/python/framework/ops.py:3471 ← operaciones TF en memoriaTodo el overhead de memoria —los 263 MB— está dentro del runtime de TensorFlow, acumulando nodos del grafo de operaciones en cada step porque el grafo no está completamente compilado. No es código de Meridian. JAX lo resuelve compilando el grafo completo una sola vez: esos 263 MB bajan a 91 MB porque no hay acumulación entre steps.
6.3 Por qué el Analyzer tarda 7.2s siempre en TF — y 0.25s en JAX
Esta es la parte que más impacta en el día a día. El Analyzer es la fase que el usuario ejecuta repetidamente cuando está explorando resultados — y con TF tarda 7 segundos cada vez.
El profiler con TF muestra esto:
246.154 llamadas a ast.py:418 (visit) → 5.9s
165.392 llamadas a ast.py:492 (generic_visit) → 4.6sLo que está pasando es que TensorFlow usa AutoGraph — un mecanismo que convierte código Python en un grafo optimizado. El problema es que lo hace en cada llamada, porque el grafo se recompila cada vez que se invoca incremental_outcome. Son casi 250.000 operaciones de análisis de código Python… por cada ejecución.
Con JAX, el mismo método tarda 0.25 segundos. La razón es simple: JAX traza el grafo una sola vez y lo reutiliza. No hay recompilación en cada llamada.
La diferencia de 7.2s vs 0.25s — 96% menos tiempo — es exactamente el coste de ese comportamiento. Y dado que el Analyzer es la fase que más se repite durante el análisis de resultados, este es el beneficio práctico más grande de cambiar a JAX en el uso habitual.
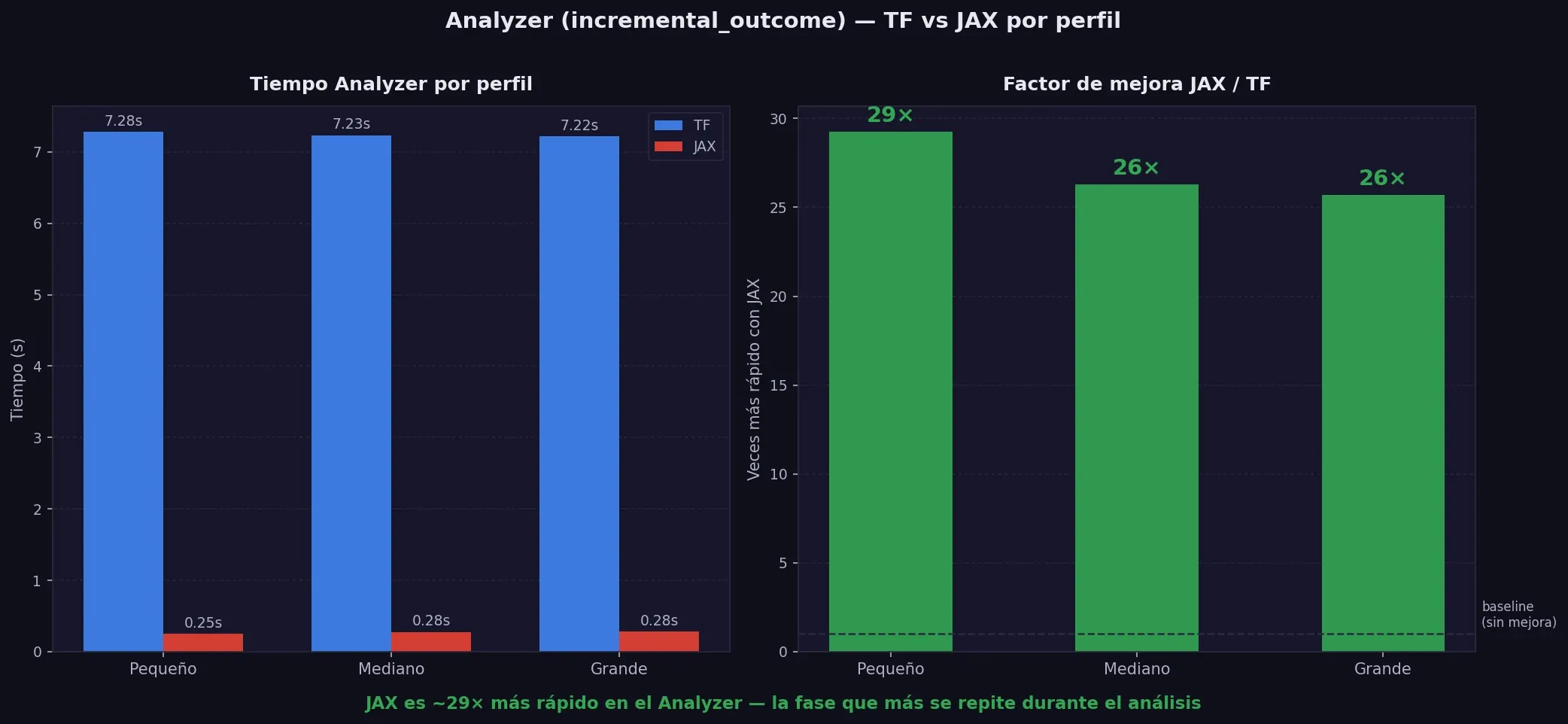
6.4 Por qué el sample_prior tarda más en JAX (~4.5s vs ~0.7s TF)
Esto puede llamar a confusión a primera vista: si JAX es más rápido, ¿por qué el sample_prior tarda más con JAX?
La respuesta es que en JAX, sample_prior incluye la primera compilación del grafo completo del modelo. En TF ese coste está diferido — se paga en la primera iteración del MCMC, no aquí. Son los mismos ~4 segundos de compilación, solo que JAX los cobra antes y TF los cobra después.
En un run de producción con 6.000 steps, esos 4 segundos iniciales son completamente despreciables. No es un problema, es solo un cambio en el momento en que se paga el coste de compilación.
6.5 Por qué el BudgetOptimizer escala con canales, no con geos
El BudgetOptimizer — la parte que calcula cómo distribuir el presupuesto entre canales — tiene un comportamiento diferente al resto. No escala con el número de geografías, sino con el número de canales de marketing.
La razón es que internamente construye una grilla de combinaciones posibles de presupuesto por canal y busca el óptimo con scipy.optimize. Cuantos más canales, más grande la grilla, más trabajo para el optimizador.
De PEQUEÑO (5 canales) a GRANDE (21 canales): 1.74s → 3.55s (+104%). Y tanto TF como JAX dan tiempos idénticos aquí, porque scipy no usa ninguno de los dos backends — corre por su cuenta.
6.6 VIF a escala extrema — solo relevante con >50 geos
Este hallazgo es interesante, pero hay que ponerlo en contexto antes de que genere alarma.
En el perfil EXTREMO (200 geos) el profiler detectó:
eda_engine.py:360 _calculate_vif → 804 llamadas → 216.7s
statsmodels.variance_inflation_factor → 38.592 llamadas → 214.7sEl VIF (Factor de Inflación de la Varianza) es un cálculo estadístico que Meridian ejecuta durante el análisis exploratorio para detectar si hay variables que se explican entre sí — lo que podría distorsionar el modelo. El problema es que lo calcula de forma secuencial: una regresión por cada geografía. Con 200 geos y 44 variables, son 804 regresiones una detrás de otra, sin paralelización.
El resultado: 216 segundos solo en este cálculo.
Ahora bien — con 50 geos o menos (que es el caso habitual en la mayoría de proyectos) el impacto es menor de 1 segundo. Solo es un cuello de botella real si el proyecto trabaja con cobertura geográfica muy granular: municipios, provincias detalladas, regiones pequeñas.
7. Qué se Puede Mejorar y Qué No
Una de las cosas que más me interesaba de este análisis era esta pregunta: ¿dónde tiene sentido invertir tiempo en optimizar y dónde no? Porque optimizar por optimizar, sin datos, es una de las formas más eficientes de perder el tiempo.
✅ Mejoras con evidencia real y ganancia confirmada
| Qué | Impacto medido | Esfuerzo |
|---|---|---|
| Migrar a backend JAX | MCMC −35-37% tiempo / −64-65% memoria. Analyzer −96% tiempo. | Mínimo — variable de entorno |
| GPU para el MCMC | 5-20× estimado (pendiente de medir) | Medio — requiere hardware |
| Paralelizar cadenas MCMC | Lineal con núcleos CPU disponibles | Bajo — parámetro ya soportado |
| VIF paralelo por geo | Alto en >50 geos. Irrelevante en casos habituales. | Bajo — joblib.Parallel |
❌ No vale la pena o directamente no aplica
| Qué | Por qué no |
|---|---|
| Rust / PyO3 sobre el MCMC | Los 263 MB de overhead están dentro del runtime de TF (ops.py), no en código Python accesible. Rust no puede tocar el interior de TF. JAX ya lo resuelve. |
| Rust / PyO3 sobre InputData | InputData tarda <0.6s con 50 geos. El cuello de botella no está aquí. |
| Reemplazar xarray en InputData | Mismo motivo. El overhead es <1s. Cambiar introduce riesgo sin ganancia medible. |
| Cambiar el algoritmo NUTS | Estado del arte para MCMC bayesiano. Sustituirlo afecta la calidad estadística. |
| Optimizar la carga de módulos | ~22s one-time por proceso. En producción se paga una sola vez. No es un problema operativo. |
| Optimizar la instanciación | ~0.7s constante, no escala con datos. No es un problema. |
8. Roadmap de Optimización — Alto Nivel
Con todo lo anterior claro, esto es lo que tiene sentido hacer y en qué orden. Todo priorizado por impacto medido y esfuerzo estimado — sin incluir nada que no esté respaldado por los datos de profiling.
Prioridad 1 — Migrar a backend JAX
Impacto: Alto. Confirmado con datos reales. Esfuerzo: Mínimo.
MERIDIAN_BACKEND=jax python tu_script_meridian.pyResultados confirmados:
- MCMC tiempo: −38% en dataset pequeño, −9% en mediano (la ganancia disminuye con el tamaño)
- MCMC memoria: −64–65% en ambos perfiles (constante, independiente del tamaño)
- Analyzer: −96% tiempo (7.2s → 0.25s) en todos los perfiles
- Sin cambios en código ni en la API del usuario
- Coste: instanciación +1.6s y sample_prior +3.8s — one-time, amortizable
El mayor beneficio práctico e inmediato es el Analyzer (−96%), que es la fase que el usuario ejecuta repetidamente durante el análisis. La mejora en MCMC depende del tamaño del dataset — mayor impacto en datasets pequeños.
Este es el único cambio que da impacto alto con esfuerzo casi cero. Debería ser el primer paso antes de cualquier otra optimización.
Prioridad 2 — GPU para el sampler MCMC
Impacto: Alto (estimado 5-20×). Pendiente de medir. Esfuerzo: Medio — requiere hardware y configuración.
El MCMC evalúa gradientes sobre matrices de datos (tensores) en cada step — exactamente el tipo de operación para la que las GPUs están diseñadas. Meridian ya soporta GPU (pip install meridian[and-cuda]). Combinar JAX + GPU es la combinación con mayor potencial, y es el siguiente paso lógico una vez migrado el backend.
Siguiente acción: medir en hardware GPU real para tener datos empíricos en lugar de estimaciones.
Prioridad 3 — Paralelizar cadenas MCMC en CPU
Impacto: Lineal con núcleos disponibles. Esfuerzo: Bajo — cambio de parámetro.
# En lugar de n_chains=4 (secuencial):
mmm.sample_posterior(n_chains=[1, 1, 1, 1], ...)
# Cada 1 se ejecuta en llamada separada — permite lanzarlos en paraleloEn una máquina de 8 núcleos se pueden ejecutar las 4 cadenas en paralelo, reduciendo el wall time a ~¼ del total.
Prioridad 4 — VIF paralelo (solo si habitualmente >50 geos)
Impacto: Alto en escala extrema. Irrelevante en la mayoría de proyectos. Esfuerzo: Bajo.
Cambiar en eda_engine.py:2061:
# Actual (secuencial):
geo_vif_da = tc_da.groupby(constants.GEO).map(
lambda x: _calculate_vif(x, eda_constants.VARIABLE, std_threshold)
)Por una implementación paralela con joblib.Parallel. Solo tiene sentido si el proyecto trabaja regularmente con más de 50 geos.
9. Datos Pendientes
Mediciones completadas
Mediciones completadas
| Medición | Resultado | Archivo |
|---|---|---|
| MCMC producción JAX — PEQUEÑO | ✅ 146s / 24ms por step / 91 MB | mcmc_jax_pequeno.log |
| MCMC producción JAX — MEDIANO | ✅ 356s / 59ms por step / 95 MB | mcmc_jax_mediano.log |
| MCMC producción TF — PEQUEÑO | ✅ 231s / 38ms por step / 263 MB | mcmc_tf_pequeno.log |
| MCMC producción TF — MEDIANO | ✅ 549s / 91ms por step / 266 MB | mcmc_tf_mediano.log |
Pendiente de medir
| Área | Relevancia | Cuándo medirla |
|---|---|---|
| MCMC con GPU | Alta — mayor potencial de mejora | Cuando haya acceso a GPU |
| Reviewer (model health checks) | Media — se ejecuta tras el posterior | En la siguiente iteración |
| Adstock aislado | Media — ¿qué % del step MCMC consume? | En la siguiente iteración |
| MCMC JAX GRANDE | Baja — completar mapa de escala | Opcional |
10. Conclusión
Pues esto es lo que da de sí un análisis de rendimiento honesto sobre Google Meridian. Voy a intentar resumir lo más importante sin perderme en los detalles técnicos.
El cuello de botella real es el MCMC, y es inevitable. No porque el software esté mal hecho, sino porque el algoritmo que usa — NUTS — es el más riguroso que existe para este tipo de modelos estadísticos. Si lo sustituyes por algo más rápido, pierdes calidad en los resultados. Ese es el trade-off, y en este caso no merece la pena.
Pero sí hay margen de mejora, y es grande. El hallazgo más importante de todo este análisis es que cambiar el backend de TensorFlow a JAX tiene un impacto real y medible sin tocar ni una línea de código del proyecto:
- El Analyzer — la parte que más se usa en el día a día del análisis — pasa de 7 segundos a 0.25 segundos. Un 96% menos.
- El MCMC en producción mejora entre un 9% y un 38% en tiempo (dependiendo del tamaño del dataset) y un 64% en memoria de forma consistente.
- El cambio se hace con una variable de entorno. Sin riesgos, sin refactoring.
Lo segundo que destaca es lo que no vale la pena optimizar. Y aquí quiero ser explícito, porque antes de hacer este análisis una de las hipótesis sobre la mesa era reescribir partes del pipeline en Rust — un lenguaje de sistemas mucho más rápido que Python — para acelerar la carga y procesamiento de datos.
Los datos lo descartan. La fase de InputData (carga y validación de datos) tarda menos de 0.6 segundos incluso con 50 geografías y 15 canales. Reescribirla en Rust requeriría semanas de trabajo, integración con PyO3 para llamarla desde Python, mantenimiento propio del código nativo… para ganar, en el mejor caso, medio segundo. El cuello de botella no está ahí, y el esfuerzo no tiene ninguna justificación con esos números.
Lo mismo aplica a la carga de módulos (~22 segundos al arrancar el proceso) o a la instanciación del modelo (~0.7 segundos). Parecen grandes cuando los ves solos, pero son costes que se pagan una sola vez por ejecución — en un run de producción con horas de MCMC, son irrelevantes.
Eso es exactamente para lo que sirve medir antes de actuar: para no invertir esfuerzo real en problemas que no existen.
¿Qué queda pendiente? La pieza que falta para tener el mapa completo es la GPU. Los estimados (5-20× sobre CPU) son prometedores, pero son solo estimados. La siguiente medición que tiene sentido hacer es JAX + GPU en hardware real — ahí es donde probablemente está la mayor ganancia que queda por confirmar.
Si estás evaluando si Meridian tiene sentido para tu proyecto, la respuesta corta es: sí, pero con JAX activado desde el principio. El coste de CPU es real en datasets grandes, y la GPU es el siguiente paso natural si el volumen lo justifica.
Nos vemos en otra, hasta la próxima.
Apéndice — Archivos de Referencia
| Archivo | Descripción |
|---|---|
/tmp/opencode/meridian_synthetic_data.py | Script principal de profiling |
/tmp/opencode/mcmc_jax_pequeno.log | Log MCMC JAX pequeño |
/tmp/opencode/mcmc_jax_mediano.log | Log MCMC JAX mediano |
meridian/meridian/data/test_utils.py | API datos sintéticos |
meridian/meridian/model/model.py:1072 | sample_posterior — entrada al MCMC |
meridian/meridian/model/eda/eda_engine.py:360 | _calculate_vif — cuello VIF |
meridian/meridian/analysis/analyzer.py:198 | Analyzer — métricas post-modelado |
meridian/meridian/analysis/optimizer.py:1393 | BudgetOptimizer — optimización presupuesto |
¿Listo para hacer crecer tu negocio?
Analicemos tu proyecto y definamos la estrategia perfecta para alcanzar tus objetivos
Solicitar consultoría gratuita